社内ドキュメントを対象としたRAGは、実務でも十分に使える技術になってきました。実際にサービスへ組み込む場面も増えています。
とはいえ、従来の構成ではベクトルDBや埋め込みモデル、同期処理などを個別に設計する必要があり、用途によっては少し重たく感じることもあります。
今回はそれらをマネージドに扱えるAmazon BedrockのKnowledge Baseを使って、最小構成で試してみました。所要時間は30分くらいです。
Knowledge Base とは?
ざっくり言うと、S3に置いたドキュメントをベクトル化して検索できるようにしてくれる仕組みです。
自前でやろうとすると
- 埋め込みモデルの選定
- ベクトルDBの構築
- チャンキングの設定
- 同期処理の実装
みたいなステップが必要ですが、Knowledge Baseはそれをマネージドでやってくれます。バックエンドのベクトルDBもOpenSearch Serverlessなどを選べます。
とりあえず動かすことだけを目的に、最小構成で試しました。
構成
- データソース:
S3 - ベクトルDB:
OpenSearch Serverless - 埋め込みモデル:
Titan Embeddings G1 - Text - 検索に使うモデル:
Claude 3.5 Sonnet
OpenSearch Serverlessはコストがちょっと怖いですが、Knowledge Base を試すだけなら問題ないでしょう(大主観)ということでやってみました。
やったこと
1. S3にドキュメントを置く
まず適当なバケット(ここではint-rag-sandboxとします)を作って、検索させたいPDFやテキストを放り込みます。今回は社内の議事録テキストを数件入れました。
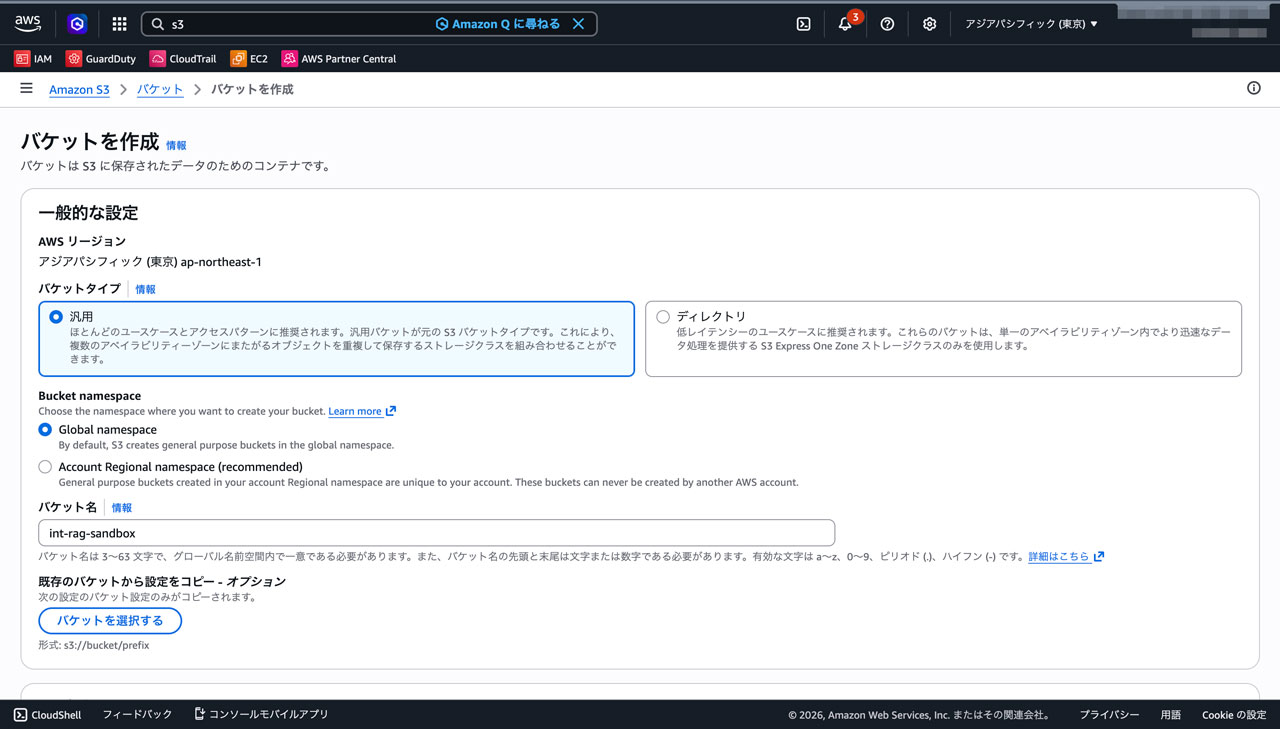
フォルダ構成は特に気にしなくて大丈夫です。
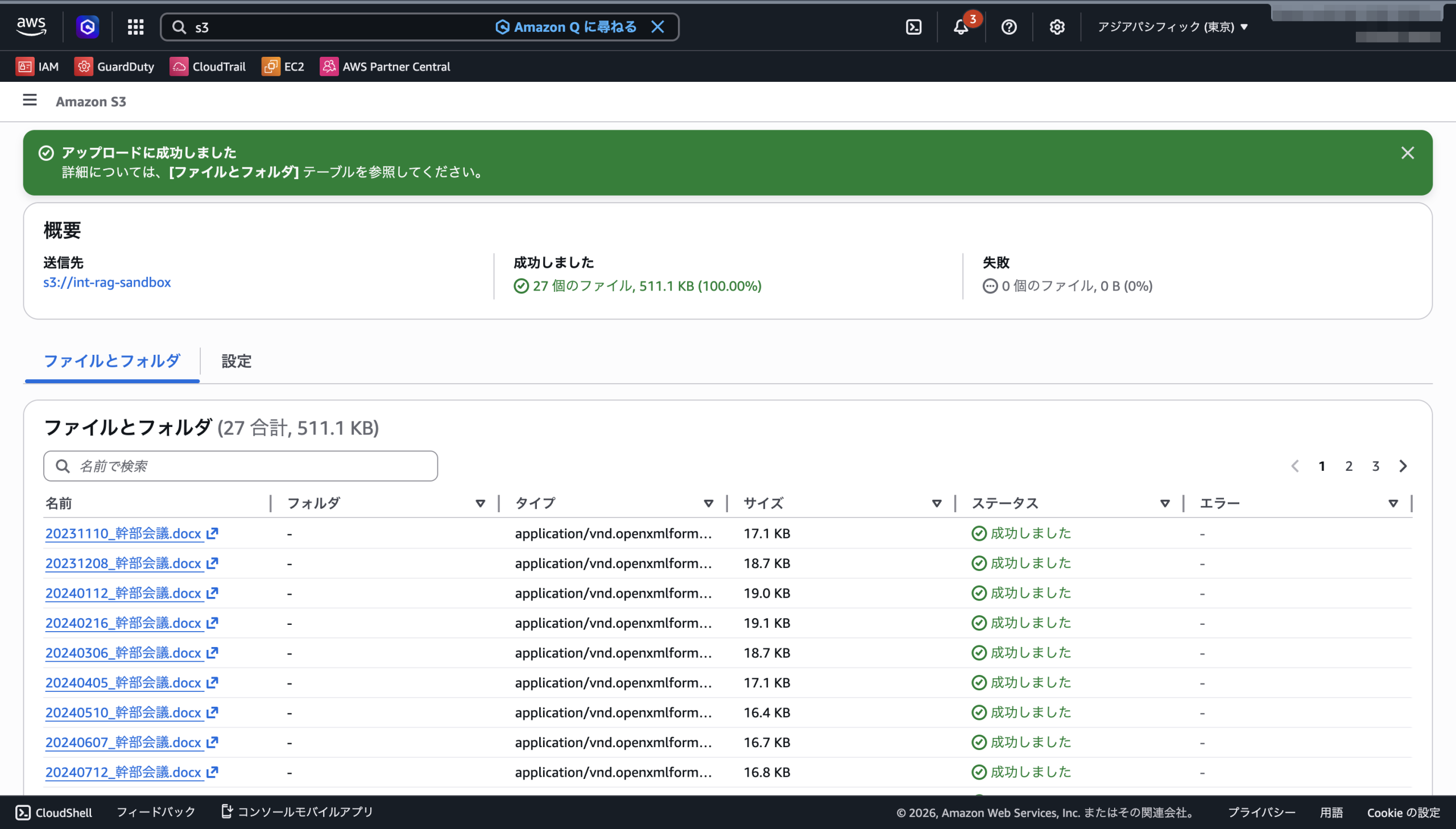
ひとまず幹部会議の議事録を2年分くらいあげてみました。
2. Knowledge Base を作成する
Bedrockのコンソールから ナレッジベース → 作成 を選びます。
今回は ベクトルストアを含むナレッジベースとします。
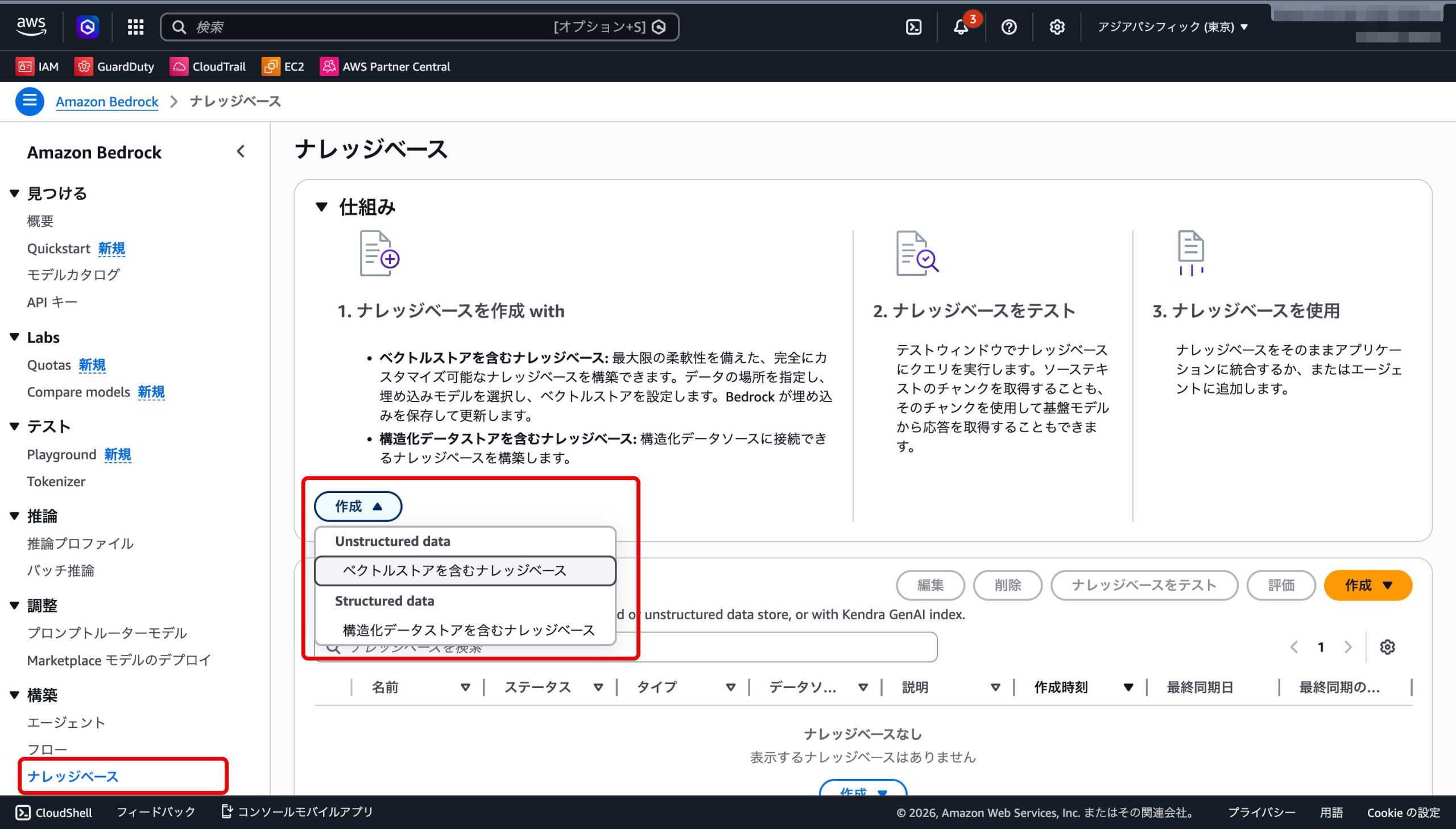
設定項目は多く見えますが、迷いどころは少ないです。
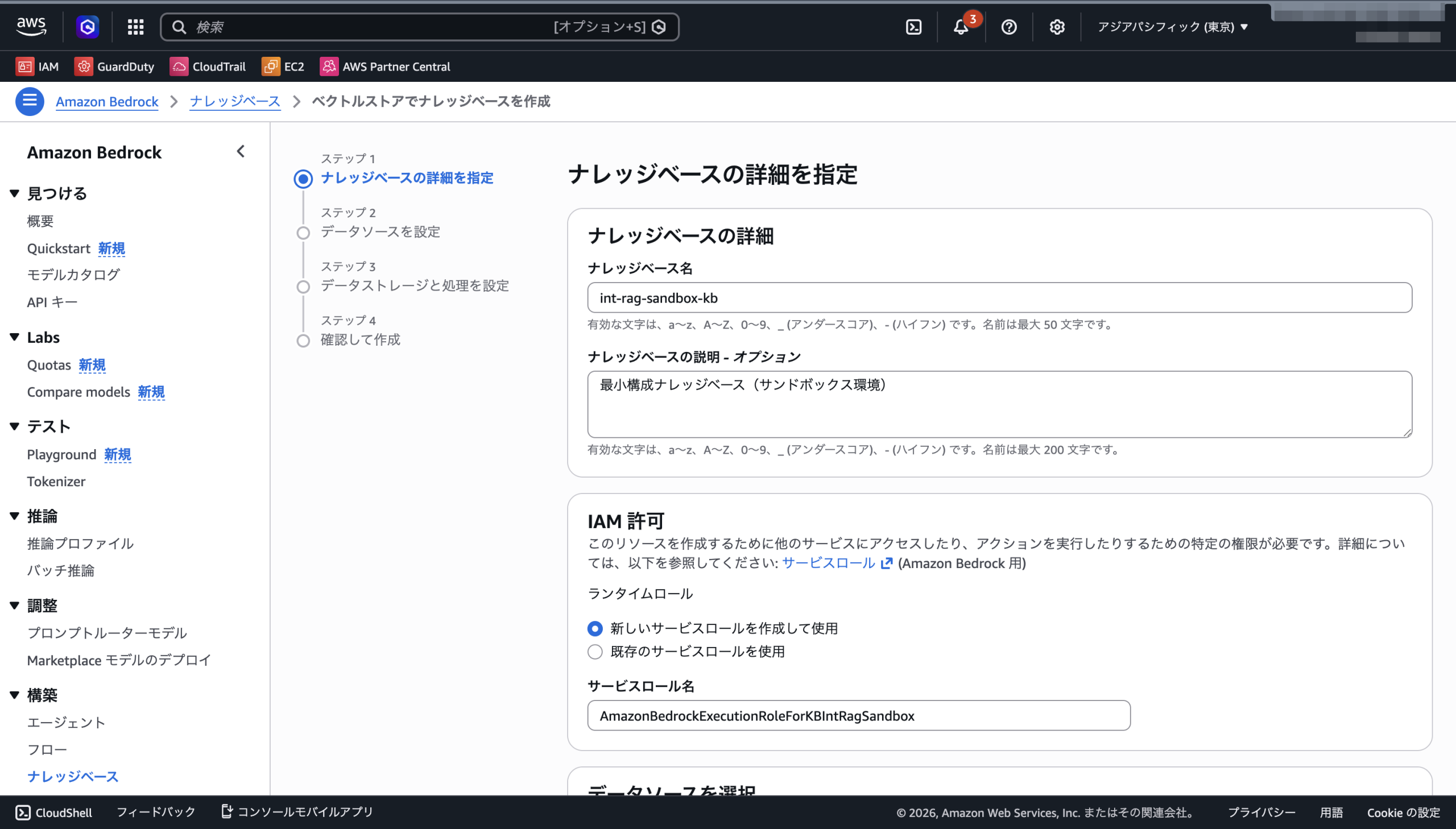
- ナレッジベース名: 適当な名前(例:
int-rag-sandbox-kb) - IAM 許可:
新しいサービスロールを作成して使用でそのまま進む(例:AmazonBedrockExecutionRoleForKBIntRagSandbox) - データソース: Amazon S3
- データソース名:
int-rag-sandbox-datasource - S3 の URI:
s3://int-rag-sandbox/
- データソース名:
- 解析戦略:
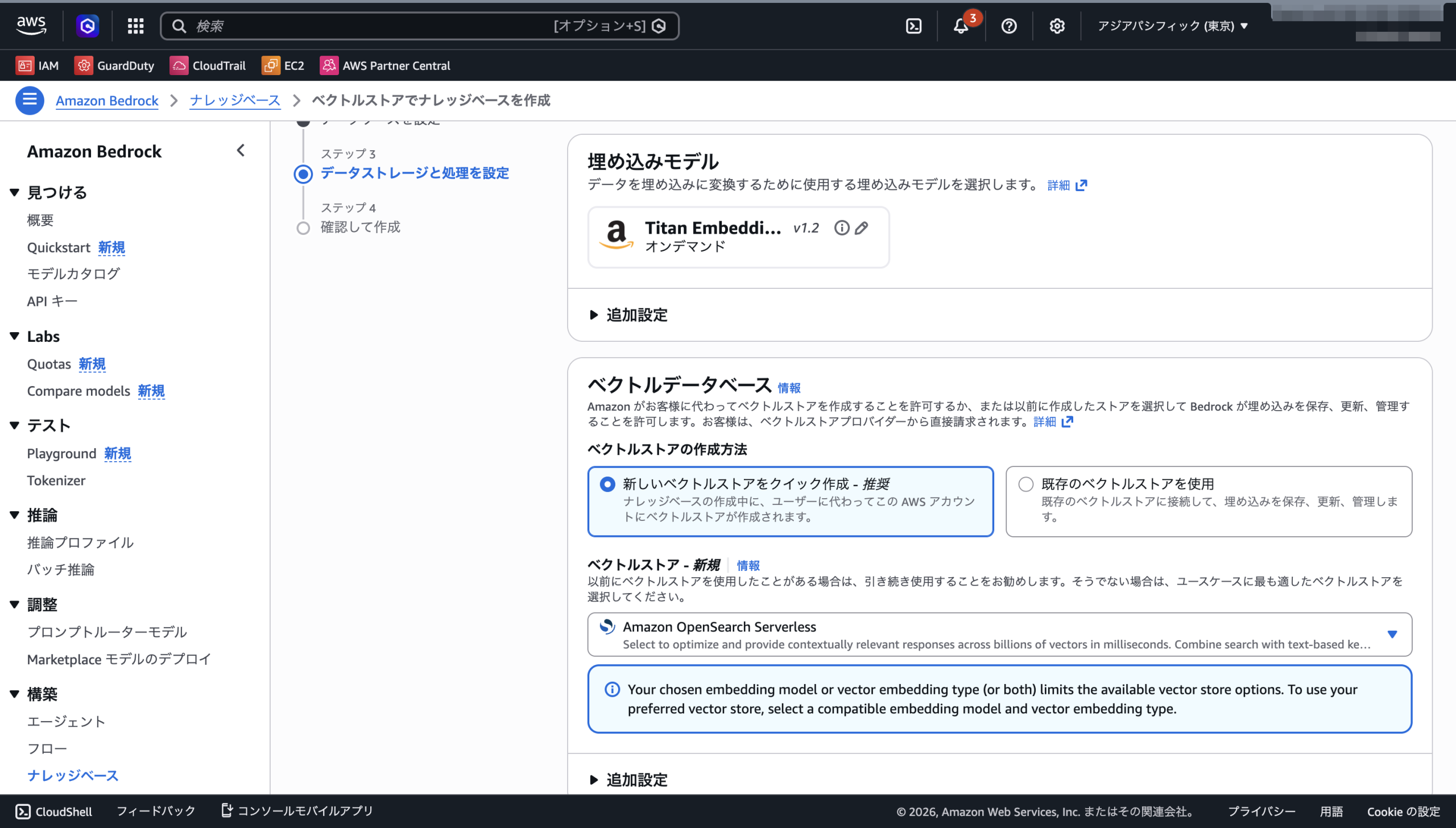
Amazon Bedrock デフォルトパーサー - 埋め込みモデル:
Titan Embeddings G1 - Text - ベクトルデータベース:
新しいベクトルストアをクイック作成 - ベクトルストア:
OpenSearch Serverless
3. データソースの同期
作成後に同期を実行します。
ドキュメントが埋め込みベクトルに変換されてOpenSearchに格納されます。
30件弱のdocxファイルで1分かかりました。
ここはドキュメント数によって変わります。
4. コンソールから動作確認
ナレッジベースの詳細画面にナレッジベースをテストというボタンがあります。ここからモデルを選んで質問を投げられます。
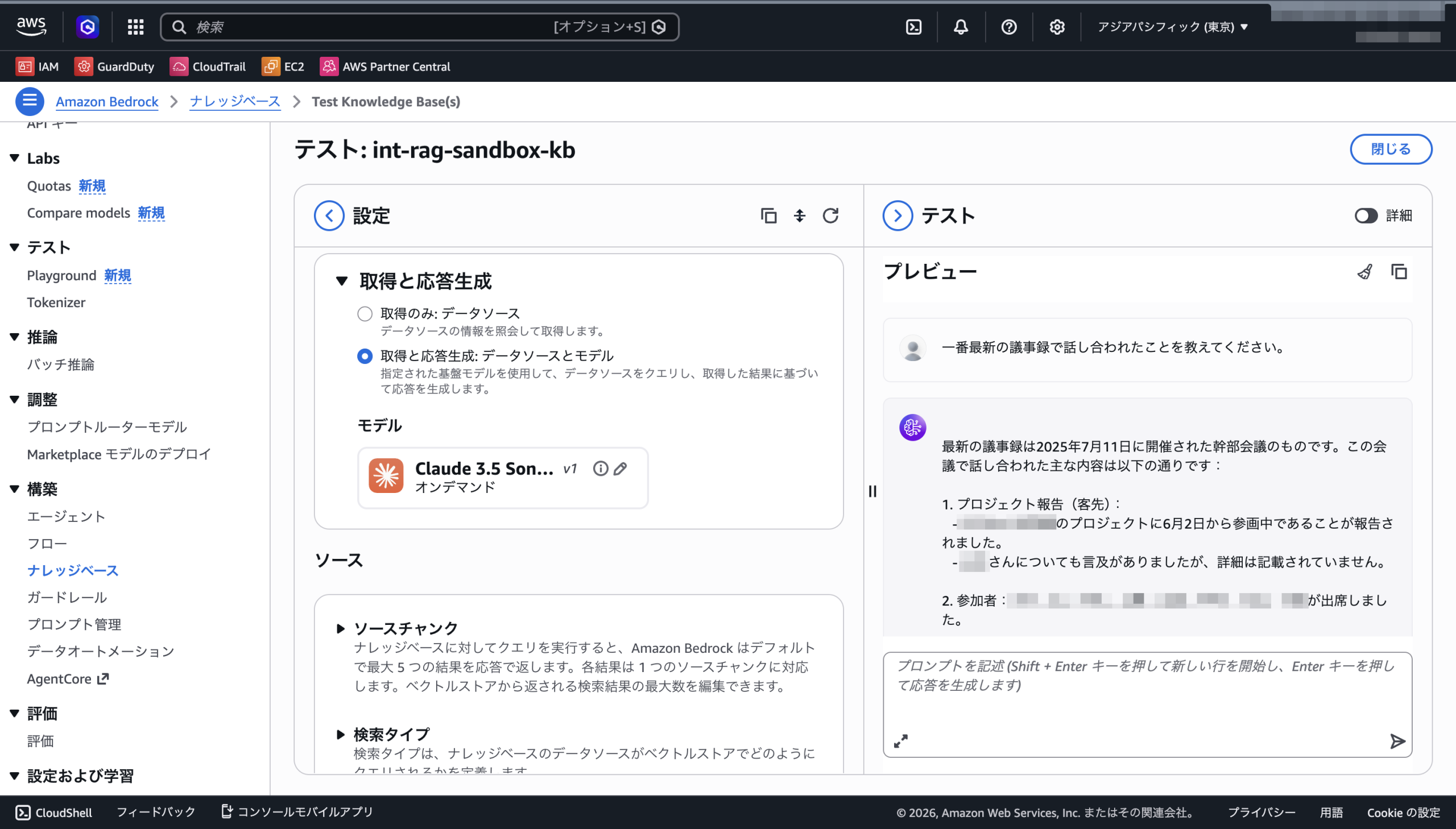
Claude 3.5 Sonnetを選択して試しに「最新の議事録で何が決まりましたか?」と投げたら、ちゃんと議事録から拾ってきた回答が返ってきました。
5. API から呼び出す
コンソールで動いたので、API経由でも確認しました。
import boto3
client = boto3.client("bedrock-agent-runtime", region_name="us-east-1")
response = client.retrieve_and_generate(
input={"text": "先月の定例で何が決まりましたか?"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "YOUR_KNOWLEDGE_BASE_ID",
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0",
},
},
)
print(response["output"]["text"])retrieve_and_generate で検索と生成をまとめてやってくれます。検索だけしたい場合は retrieveメソッドが別にあります。
所感
RAGというとどことなく難しいイメージがありますが、コンソールからの設定で簡単に動きます。自社のドキュメントを使ったRAGを検討している方はぜひ試してみてください。
チャンキングの設定やメタデータフィルタリングなど細かい調整もできますので、次は精度を上げる方法をご紹介します。
ここまで読んでいただき、ありがとうございます。もしこの記事の技術や考え方に少しでも興味を持っていただけたら、ネクストのエンジニアと気軽に話してみませんか。
- 選考ではありません
- 履歴書不要
- 技術の話が中心
- 所要時間30分程度
- オンラインOK
